I just realized Veeam is probably called that because of “VM.” Vee-M. Veeam. I’m a smart guy.
I’ve had Veeam Community Edition for awhile now. I’ve mainly used it to do one-off backups of ESXi VMs. I think the first time I used it was when I was resizing a VM. I think I made it too large and needed to shrink it down. Which will be a theme here. In case I messed up, I backed it up beforehand. Working directly with VM configuration files through text editors and CLI, there was a high chance of that. But I never had to rely on the backup, luckily.
My goal this time, however, was to setup regular, scheduled backups of my important VMs:
- Windows Server DCs
- Pi Hole
- UPS VM
- Ubuntu Server
I had a spare 4TB external HDD lying around, so I chose to use that as the storage repository. I could’ve gone the way of creating another VM and installing Veeam on it, but for some reason, that seemed…odd? I wouldn’t back up that “Veeam VM” anyway. But some cursory searching online yielded recommendations of using a separate physical device as the host. So that’s what I did.
I had an old Intel NUC that I rescued from eWaste from my last job as we were moving out. It was used to drive a display board in our lobby. It has 4GB of RAM, 120GB SATA SSD, and a Celeron Nxxx CPU. Not sure exactly what model. A bit scant on power, but it was fine for Ubuntu and Internet connectivity.

But enough for Veeam? And Windows 11? Only one way to find out.
I chose Windows 11 since the Windows 10 End of Life is in October. I’m slowly moving my devices that way, but that’s another story. Installing Windows 11 did take quite awhile. And even just signing-in to the desktop was slow.
After running Windows Updates, which again was slow, I wanted to install Veeam 12 Community Edition, the latest version. Unfortunately, Veeam’s website is awful. Trying to find the download link required me to give my email address. And I still didn’t get an email. Luckily, I saved the ISO of version 11, so I installed that version.
I connected the 4TB external drive to the NUC, and then in Veeam, added that as a backup repository. Following that, I tried adding my ESXi host, for which I had to provide username and password. All the VMs appeared!
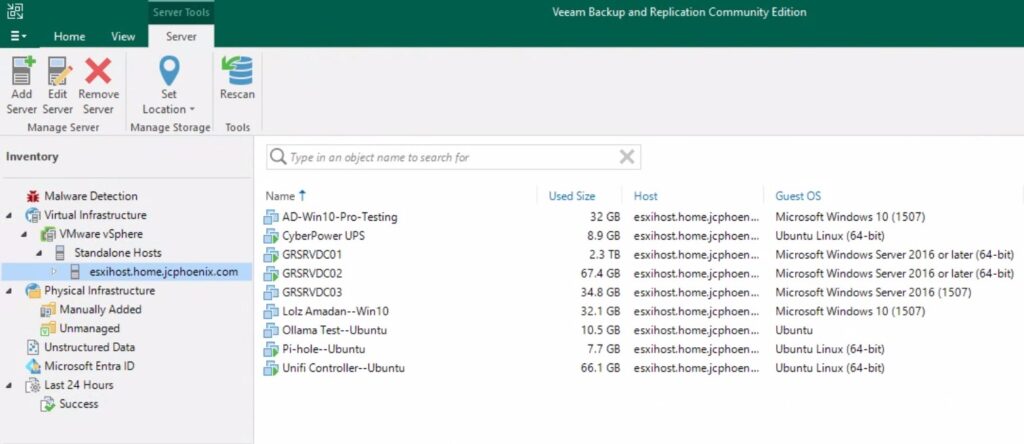
Next, I set up a test backup run. For this target, I chose a smaller VM: my Linux-based VM that hosted the UPS monitoring system. This VM was thin-provisioned at 20GB, but only about 7GB was being used at the time.
After a few minutes, it completed successfully! Lastly, I set up a schedule for daily backups. None failed for the the few days I let it run. I got some warnings, but they were about limited space on the ESXi host. Which I knew about; the ESXi datastore is like 90% filled.
After those successful backups, I decided to upgrade to the latest version. Unfortunately for me, I had to do a 2-step process up upgrades. My version of Veeam 11 was old enough that I couldn’t go directly to v12. I had to do an intermediate step.
Once that was done, and once I found the download link for Veeam 12, I attempted the installation. Sadly, when the installation was almost done, I received an error that some Veeam service couldn’t be started. I should note that this NUC was so slow, that it took forever to install. I’m talking at least 2hrs. I think it would’ve been faster with a beefier computer. So it took me a few days to try all this Anyway, after a reboot, I tried again to upgrade, but I got the same issue. This time, I took note of the service that wouldn’t start: some Veeam threat hunter. To be fair, the upgrade installer did warn me about potential issues with existing AV. I ended up turning off Windows Defender and system security during the installation. That seemed to solve the issues on my final upgrade attempt. I turned security back on afterwards.
With everything finally up-to-date and my test backup successful, it was time to do it for real. I had five VMs I wanted to backup. I could’ve set an individual backup job for each VM. But I also had the ability to include multiple VMs within a single job. Once again, I went to the Internet. I found a post on reddit, where the suggestion appeared to be grouping similar OSs together. Apparently this helped with deduplication, since many system files of VMs with similar OSs will be the same.
The downside, however, appeared to be potentially higher chances for corruption. If a backup job got corrupted, multiple VMs could be affected at the same time. But I figured since I was storage space-constrained with my 4TB external HDD, more deduplication would be more advantageous.
So I created two jobs:
- 3 Linux-based OSs – Ubuntu Server, UPS VM, and Pi Hole; I called these “Services.”
- 2 Windows Servers – the DCs and fileserver; I called these “Windows”.
I also had to set the schedule and retention. For both jobs, I chose weekly backups. One on Monday, the other on Wednesday, but both starting at midnight. For retention, I kept the following for Services:
- 21 days of backups
- 4 weekly full backups at all times.
- 6 monthly full backups at all times.
- 1 yearly full backup at all times.
While for Windows, I opted to keep backups for 21 days, with 1 yearly full backup kept at all times. I’d like to keep more, but I’m storage space constrained.
I then created my initial backup of each by running each job manually. Both were successful. The Windows backup was quote long at 9hrs. The main reason being that the primary Windows Server VM, which was also the fileserver, was thick-provisioned for 2.3TB. Even though I’m only using less than 1TB total. When I created the VM, I mistakenly chose thick-provisioning. Which is why the ESXi datastore is almost full. For reference, the secondary Windows Server VM is only about 80GB thin-provisioned.
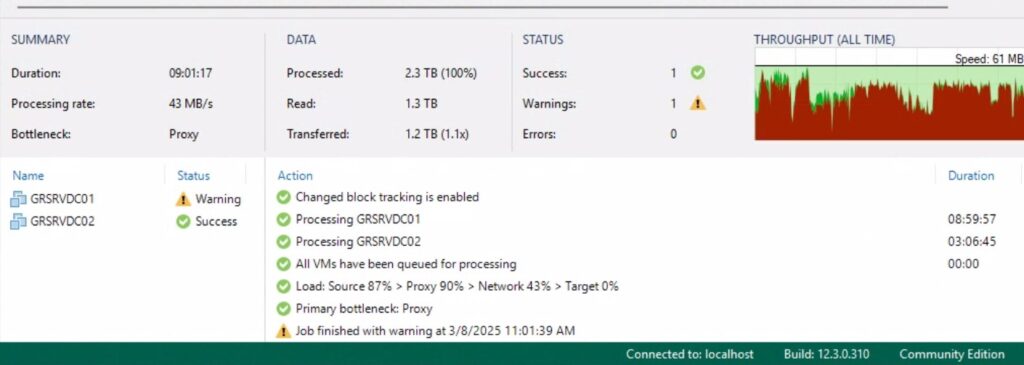
Which is a big reason I’m doing this. Because I need to resize that Windows Server VM. And before I do that, I want to make sure I have a backup. I also want to redo the physical server’s drive configuration. I want to add a new HDD to the virtual drive or RAID pool. Which for some reason, I can’t do right now. I’ve ordered a new RAID card to see if that’ll help.
I also want to think about the retention policy some more. I quickly set the number of retained full backups without really thinking too much about it.
That said, before I even do that, I really need to test the backup. Same with a Windows Server backup I’ve been doing on the primary server VM. But given my current storage constraints, I’m not even entirely sure how I’m going to do that. I think that’ll be the next thing I work on.